(Post original en Medium. Esto es para archivo.)
Siguiendo con esta serie de artículos de divulgación sobre ciencia de datos, ya pudimos instalar y configurar nuestro entorno para Apache Zeppelin. El siguiente paso será hacer algo de análisis de datos “real” con Spark y Zeppelin. Para ello, vamos a arrancar con lo básico para hacer análisis de datos: veremos el código básica para cargar los datos y limpiarlos (también conocido como ETL o “extract, transform and load” en la jerga).
Obteniendo el conjunto de datos
Creo honestamente que a la hora de aprender cosas de ciencia de datos es mejor concentrarse en un problema que nos parezca interesante. Por supuesto, podría apuntar a algo genérico y hacer un análisis del conjunto de datos de las flores iris, o explorar el conjunto de datos de pasajeros del Titanic. Sin embargo, no estoy buscando hacer una serie de tutoriales genéricos de los cuáles hay muchos ya.
Lo bueno de exploración de datos es que el conjunto de datos no importa mucho. Cualquier conjunto es candidato a ser explorable. Por ejemplo, en una de mis primeras experiencias con Spark, como proyecto final de una materia, hice análisis de temas de las propuestas de ley de la cámara de diputados de la Nación Argentina (queda pendiente revisar y actualizar ese proyecto y hacer un artículo al respecto). Obtener resultados interesantes a partir del conjunto de datos elegidos ya es otra historia. Pero incluso un resultado negativo explorado vale más que uno positivo sin explorar.
Para los ejemplos que llevaré a cabo decidí revisar el repositorio de datos abiertos de la Secretaría de Modernización de la República Argentina. Hay varios conjuntos de datos de distinta índole y en varias categorías. Como soy originalmente de una región donde la lechería tiene mucho impacto socio-económico (la mayoría trabaja alrededor de eso), decidí ir por un conjunto de datos de elaboración de productos lácteos, particularmente sobre elaboración de productos lácteos sólidos.
Descargué el conjunto de datos y me encontré con el primer problema, la codificación. Es un problema con el que, trabajando en español, suelo encontrarme. Muchas de las cosas están codificadas para el formato ISO-8859–1, una codificación ASCII con la que no me gusta mucho trabajar, prefiero mucho más la codificación UTF-8 de Unicode (he tenido menos problemas lidiando con el último a la hora de analizar texto). Si quieren entender un poco la diferencia entre ambos, a mi en particular me gusta esta respuesta de Stackoverflow, pero depende de ustedes cambiarlo o no.
En mi caso, previo a trabajar con un conjunto de datos, siempre verifico que tipo de codificación tiene y, si no es UTF-8, lo transformo. Todo eso puede hacerse con los siguientes comandos en un entorno *nix:
$ file productos-lacteos-solidos.csv
productos-lacteos-solidos.csv: ISO-8859 text, with CRLF line terminators
$ iconv -f iso-8859-1 -t utf-8 productos-lacteos-solidos.csv > productos-lacteos-solidos.utf8.csv
Ahora el archivo productos-lacteos-solidos.utf8.csv tiene la codificación que quiero y puedo comenzar a trabajar.
Cargando los datos en un Notebook de Zeppelin
Levantando la instancia de Zeppelin
Ya tengo mi archivo con datos. El primer paso es arrancar Zeppelin, crear un notebook y cargar el archivo. Si bien Zeppelin puede ser instalado directamente en su máquina, como habrán visto en mi publicación anterior, yo prefiero utilizar Docker. Luego, levando mi instancia de Zeppelin con el siguiente comando:
$ docker run -d --rm -p 8080:8080 -v $PWD/datos:/data -v $PWD/notebook:/notebook -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.7.3
Este comando tiene un poco más de cosas que el que les había mostrado en el artículo anterior:
-v $PWD/datos:/dataEsto lo utilizo para decir que el directoriodatosen el directorio actual de mi máquina estará mapeado al directorio/datade la instancia de Docker. Es en ese directorio donde tendré el archivoproductos-lacteos-solidos.csvque cargaré en el notebook de Zeppelin.-v $PWD/notebook:/notebookEsta y la siguiente opción sirven para establecer dónde guardar los notebooks localmente (persistencia), así no son borrados una vez que la instancia de Docker finalice. En este caso mapeamos el directorio localnotebook, que se encuentra dentro del directorio actual, al directorio de la instancia de Docker en/notebook.-e ZEPPELIN_NOTEBOOK_DIR='/notebook'Esta es la otra mitad del comando anterior. Lo que hace es avisarle a Zeppelin que guarde sus notebooks dentro del directorio/notebookde la instancia de Docker.
El resto de los comandos son más clásicos de Docker. Para aprender a utilizar Docker en un entorno de ciencia de datos les puedo recomendar este artículo. Eventualmente intentaré hacer uno similar en español, pero todo a su tiempo.
Una vez que tenemos nuestra instancia de Docker funcionando, ingresamos a http://localhost:8080 donde podremos acceder a Zeppelin y allí crearemos un nuevo notebook (si no carga al principio puede que Docker esté tardando un poco más en levantar la imagen, sólo esperen un rato y vuelvan a intentarlo).
Cargando los datos
Una vez creado el notebook ya estamos en condiciones de comenzar a trabajar con Spark. Cargamos los datos con lo siguiente:
val dataset = spark.read.format("csv")
.option("sep", ";")
.option("inferSchema", "true")
.option("header", "true")
.load("/data/productos-lacteos-solidos.csv")
Vamos paso a paso explicando que hace cada línea (en realidad es una sóla línea conectada, donde a cada salida se le aplica un nuevo método hasta obtener un resultado final):
spark.readEs necesario para decir que vamos a leer de alguna fuente.format("csv")Da cuenta del formato que estamos utilizando (en este caso un archivo csv).option("sep", ";")Establece que el separador de campos en el archivo de datos es punto y coma en lugar de coma (el que viene por defecto).option("inferSchema", "true")Establece que Spark trate de inferir que tipo de datos tiene cada columna (e.g. entero, cadena de caracteres, etc). Esto muchas veces sirve si los datos están limpios y sabemos bien que hay en cada columna. Si el algoritmo que infiere el tipo de datos no puede decidirse, definirá a la columna por defecto como tipo string (o cadena de caracteres) y dependerá de nosotros revisarlo.option("header", "true")Esta opción establece que el archivo de datos tiene un encabezado (i.e. el nombre de cada una de las columnas) en la primera línea.load("/data/productos-lacteos-solidos.csv")Esta es la parte que verdaderamente carga el conjunto de datos que será asignado a la variabledataset.
Por si no se dieron cuenta, este código está escrito en Scala. También hay interfaces para otros lenguajes de programación, los invito a aprender y utilizar su favorito.
Ahora que tenemos los datos cargados, podemos hacer un par de revisiones. En particular estoy interesado en dos:
dataset.printSchema()
Este nos muestra el esquema que, en este caso, Spark pudo inferir sobre los datos:
 Esquema inferido del conjunto de datos
Esquema inferido del conjunto de datos
Como vemos, nos muestra cada columna (por nombre, de acuerdo al encabezado del archivo) y su tipo. En particular, vemos que la columna Cantidad fue mal inferida (claramente el tipo debería ser un número entero o flotante). Ya pasaremos a lidiar con eso en unos momentos.
Por otro lado, el siguiente comando:
dataset.show(5)
Nos muestra el siguiente resultado:
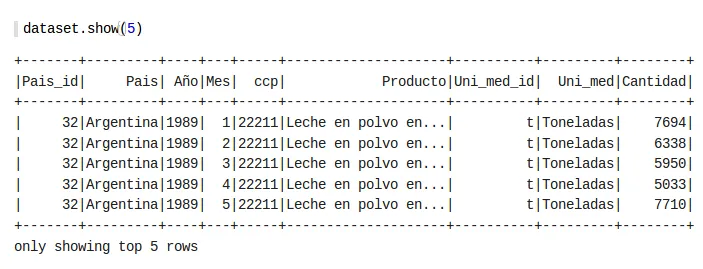 Primeras 5 filas del conjunto de datos
Primeras 5 filas del conjunto de datos
Es una tabla muy cómoda de revisar que muestra los primeros 5 registros del conjunto de datos para todas las columnas.
El notebook, como lo tenemos hasta ahora, puede verse en la siguiente imagen:
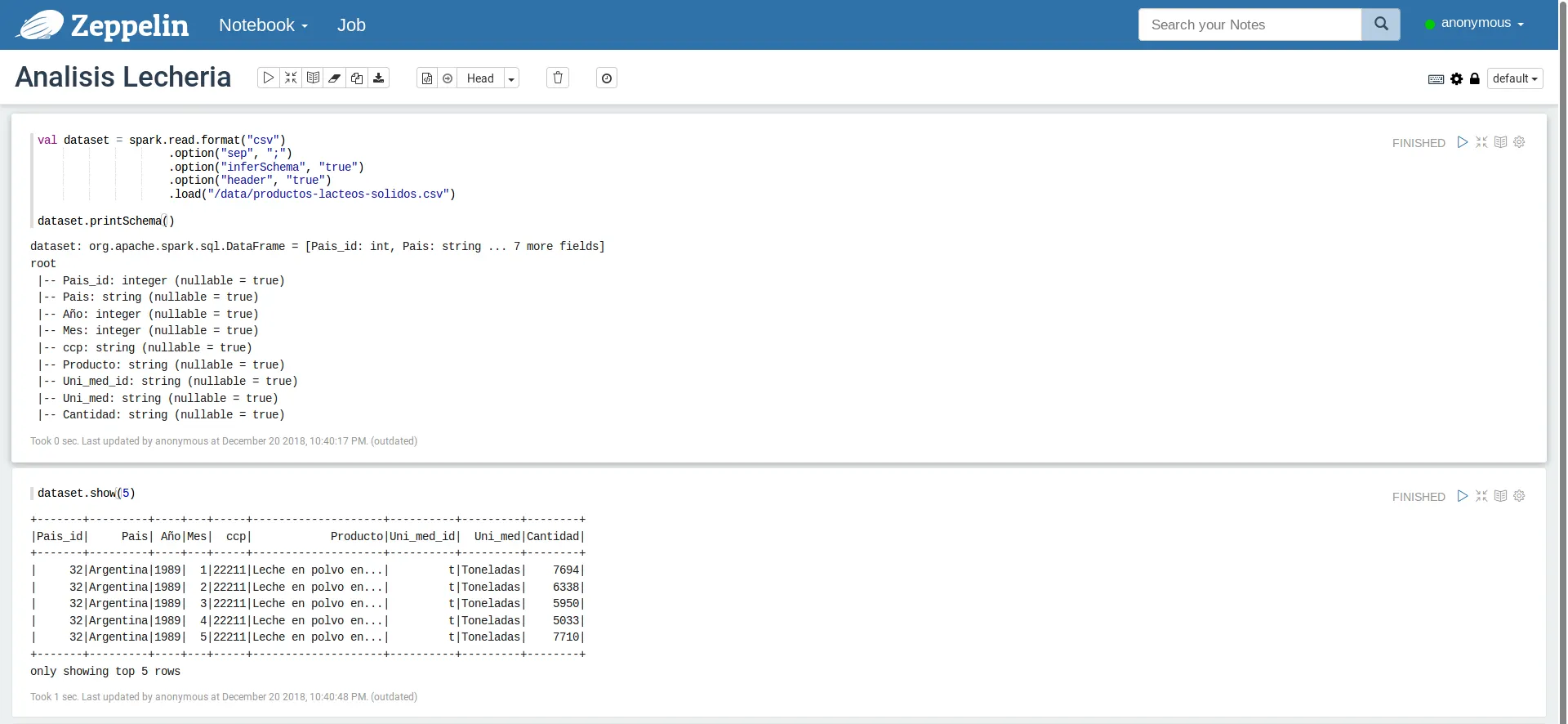 Carga y muestra inicial de datos
Carga y muestra inicial de datos
Limpieza de datos
Bueno, como vimos anteriormente, hay algo que no permitió inferior la columna Cantidad como algún tipo de dato numérico. Podemos intentar hacer una exploración muy sencilla para ver que tipo de datos está teniendo dicha columna, se hace con el siguiente comando:
z.show(dataset.select($"Cantidad").distinct)
Analicemos esta línea:
z.showes algo específico de Zeppelin (no de Spark) y sirve para que los datos sean interpretados por el notebook para ser mostrados en un formato “amigable” para revisar.dataset.select($"Column")es realmente el comando que nos interesa a la hora de analizar los datos. En primer lugar hacemos referencia al conjunto de datos. Luego seleccionamos (medianteselect) la columnaCantidad. Prestar atención al operador$, que es un operador especial de Spark para convertir un string en una columna (en este caso no es particularmente necesario, pero a medida que utilicen Spark más y más se darán cuenta la utilidad de dicho operador, por lo que es bueno que lo comiencen a utilizar ya)..distincteste operador selecciona valores únicos (no repetidos), lo que hace más corta la cantidad de valores que tenemos que ver.
Si ven una similitud entre los operadores utilizados en el código Scala y las operaciones de SQL, claramente entenderán que no se trata de un simple coincidencia. Mucho del análisis de datos (tanto en Spark como en otros frameworks para tal fin) está construido sobre la base de SQL y, en particular para Spark, es muy fácil (y hasta recomendable) intercambiar los lenguajes. Veremos más de esto más adelante.
Este comando nos muestra una tabla muy sencilla y que podemos recorrer (scrollear) a nuestro gusto, lo que facilita mucho a la hora de hacer un vistazo rápido para entender que datos tiene la columna Cantidad:
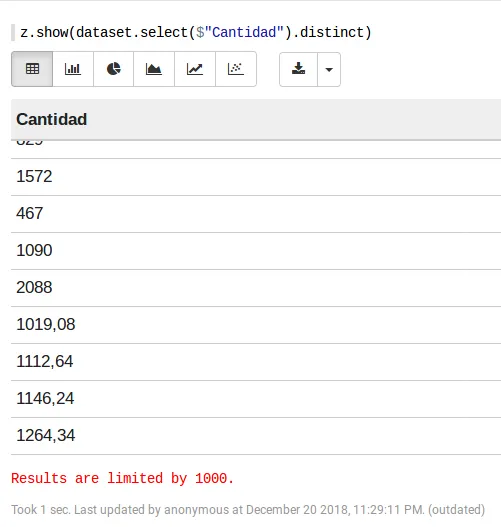 Resultado de revisar la columna "Cantidad"
Resultado de revisar la columna "Cantidad"
La imagen previa nos muestra la salida del comando anterior. Por suerte no hace falta revisar mucho para encontrar la razón por la cual Spark no pudo inferir que Cantidad se trataba de una columna numérica porque los números decimales tienen , en lugar de . (otro de los tantos problemas al trabajar con datos de origen no inglés). Por suerte, si forzamos una conversión, Spark si logra transformarlos sin mayores problemas. Luego, con el siguiente comando podemos forzar la conversión de la columna Cantidad en una columna de tipo flotante:
dataset.withColumn("Cantidad", $"Cantidad".cast("float"))
Dónde withColumn básicamente sirve para crear una nueva columna en el dataset (en este caso reemplazando a la columna Cantidad, al llamarse igual como establece el primer parámetro de withColumn) que tenga los valores de Cantidad pero en formato flotante. Luego, al hacer z.show de lo anterior obtenemos lo siguiente:
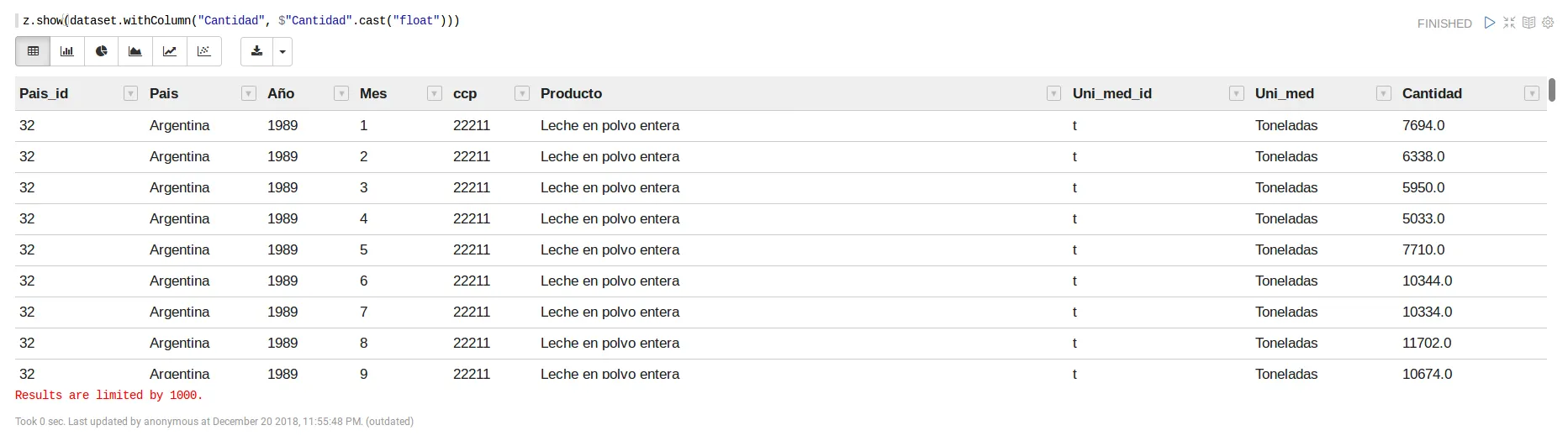 Resultado de convertir la columna Cantidad en flotante
Resultado de convertir la columna Cantidad en flotante
De la misma forma que revisamos esta columna, lo podemos hacer con otras columnas. Por ahora lo vamos a dejar aquí.
Pueden notar la leyenda roja en las últimas dos imágenes. Los resultados que muestra Zeppelin a través de z.show son 1000 por defecto. Esto es para evitar sobrecargar la memoria.
Guardando los datos
El siguiente paso será guardar nuestros datos “limpios”. Para eso haremos uso de un formato especial que tiene Apache llamado parquet. Es un formato tabular pensado para Apache Hadoop. Es la forma recomendada de guardar datos a un archivo mientras se utiliza Spark (ya que los csv suelen tener problemas para ser manipulados, sobre todo a la hora de trabajar con grande volúmenes). Parquet, además de guardar la información de los datos guarda otra meta-información como el esquema (útil a la hora de cargar los datos nuevamente puesto que hace que el proceso sea más rápido).
Para guardar los datos se utiliza el siguiente comando:
dataset.withColumn("Cantidad", $"Cantidad".cast("float"))
.write.format("csv").save("/data/datos-lecheria.parquet")
¡Listo! Ya tenemos guardados nuestros datos. Estos los retomaremos en la próxima entrega de esta serie de artículos donde veremos como hacer algo de visualización y exploración de datos con Spark.
Nuevamente, ¡gracias por leer y compartir!