(Post original en Medium. Esto es para archivo.)
Siguiendo con esta serie de artículos sobre como trabajar con Spark, luego de haber cargado y limpiado los datos, procedemos a hacer algo de análisis sencillo de datos y visualización de los mismos utilizando las herramientas provistas por Apache Zeppelin.
Cargando y mostrando los datos usando SQL
Una de las ventajas de Spark es su interoperatividad con SQL (el mismo lenguaje para hacer consultas sobre bases de datos). Esto nos sirve para hacer varias consultas básicas (e.g. para calcular estadísticas como promedio, suma, cantidad, etc.) de manera sencilla. Para ello sólo tenemos que hacer uso del módulo Spark SQL que ya viene junto con Spark.
Iniciamos la actividad levantando nuestro servidor de Zeppelin como vimos en el capítulo anterior de esta entrega:
$ docker run -d --rm -p 8080:8080 -v $PWD/datos:/data -v $PWD/notebook:/notebook -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.7.3
Y luego accedemos a http://localhost:8080 y buscamos nuestro notebook (que guardamos en la sesión anterior con el nombre “Análisis Lechería”, o similar).
Si recordamos, la clase anterior habíamos limpiado el notebook y guardado un archivo de extensión .parquet. Para aprovechas el trabajo hecho, esta vez, en lugar de cargar el .csv (que vimos que tenía ciertos datos mal), cargaremos el archivo .parquet que tiene los datos limpios. Eso lo hacemos con la siguiente línea:
val dataset = spark.read.load("/data/datos-lecheria.parquet")
Por supuesto, la dirección al archivo variará de acuerdo a su máquina, pero asumiendo que siguieron (e hicieron) el tutorial con Docker, debería ser la misma que la mía. Ahora bien, podemos ver el esquema del conjunto de datos con el método .printSchema() (en este caso, como el esquema se guarda en los metadatos del .parquet no es necesario inferir nada). También podemos ver los primeros registros del dataset con el método .show(). Lo que deberían tener es algo parecido a lo siguiente:
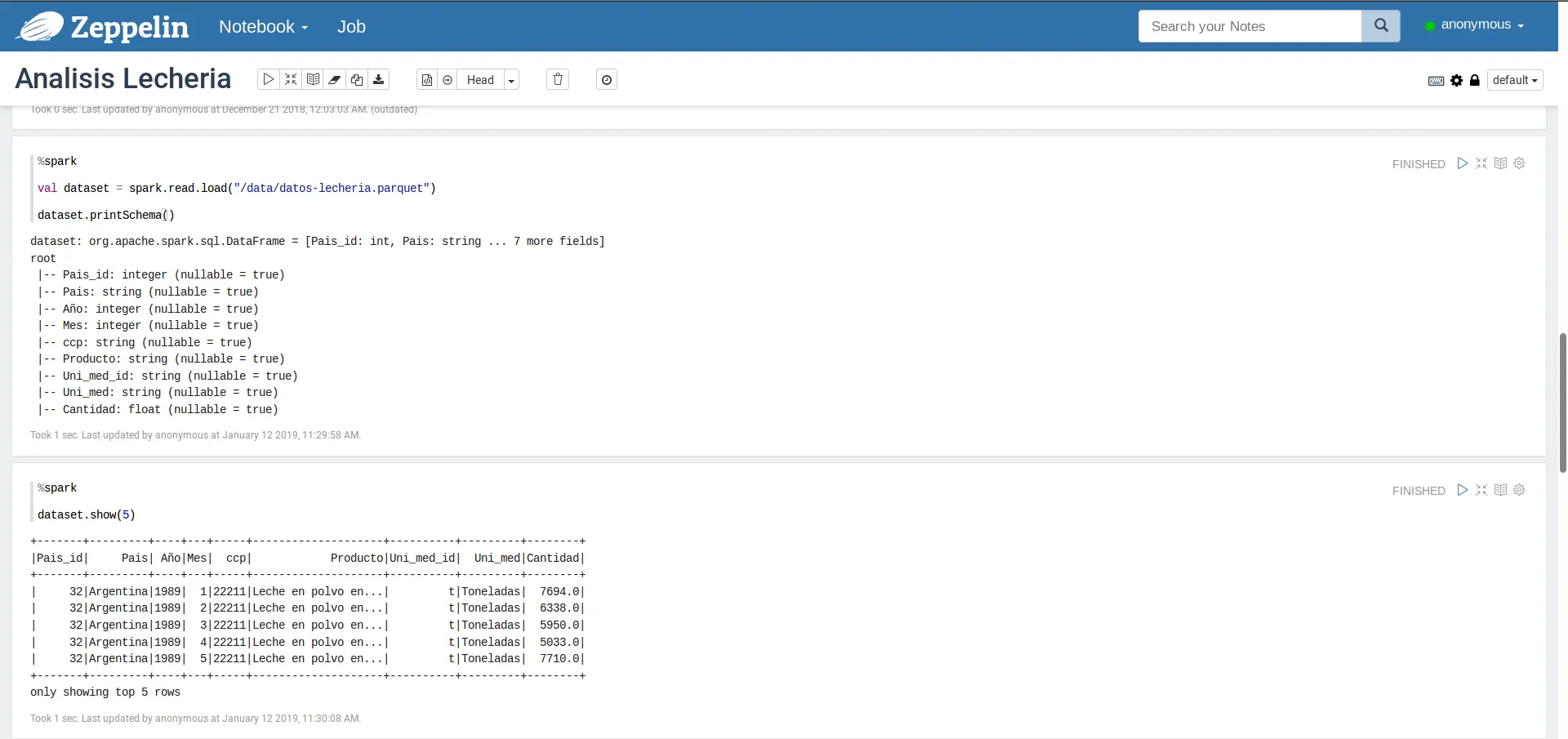 Cargando y mostrando datos de la sesión anterior
Cargando y mostrando datos de la sesión anterior
Como vemos en la segunda celda del notebook (para el que no lo sepa, las celdas son las unidades básicas ejecutables donde escribís código), al mostrar los primeros 5 registros del dataset, vemos que forman una tabla. Bueno, esta puede ser tranquilamente pensada (y, más importante, procesada), como una tabla de SQL. Luego, si queremos hacer lo mismo de esta celda, con SQL, podemos ejecutar la siguiente línea:
SELECT * FROM dataset LIMIT 5
Sin embargo, escribiendo esta línea en una celda aleatoria, puede lanzar errores. Y es que primero tienen que decirle a Zeppelin que dicha celda debe interpretar el código utilizando SQL. Para ello, en una celda nueva, y antes de escribir nada (i.e. antes de escribir su consulta SQL), deben poner en la primera línea de la celda el comando %sql, lo que le dirá a Zeppelin que el código de la celda será interpretado como tal. Nota: Salvo que ustedes cambien la configuración, el código por defecto de la celda es interpretado como Scala Spark, lo que es equivalente a poner un %spark en la primera línea.
Ahora, si ejecutan la celda, no les tirará error de sintaxis, pero seguramente lanzará otro error, que básicamente les dice que la tabla no existe. El último paso previo a empezar a generar consultas sobre un dataset en Spark, es registrarlo para SparkSQL. Esto se hace desde una celda de Spark, con el siguiente comando:
dataset.createOrReplaceTempView("lecheria")
Donde el primer dataset es la variable que tiene el conjunto de datos con el que quieren trabajar y "lecheria"que se encuentra entre paréntesis es el nombre que tendrá la tabla (técnicamente será una “vista” en este caso) para el intérprete SparkSQL.
Ahora sí, si ejecutan el comando SQL de más arriba obtendrán un resultado similar a lo mostrado por dataset.show(5). El notebook debería quedarles más o menos así:
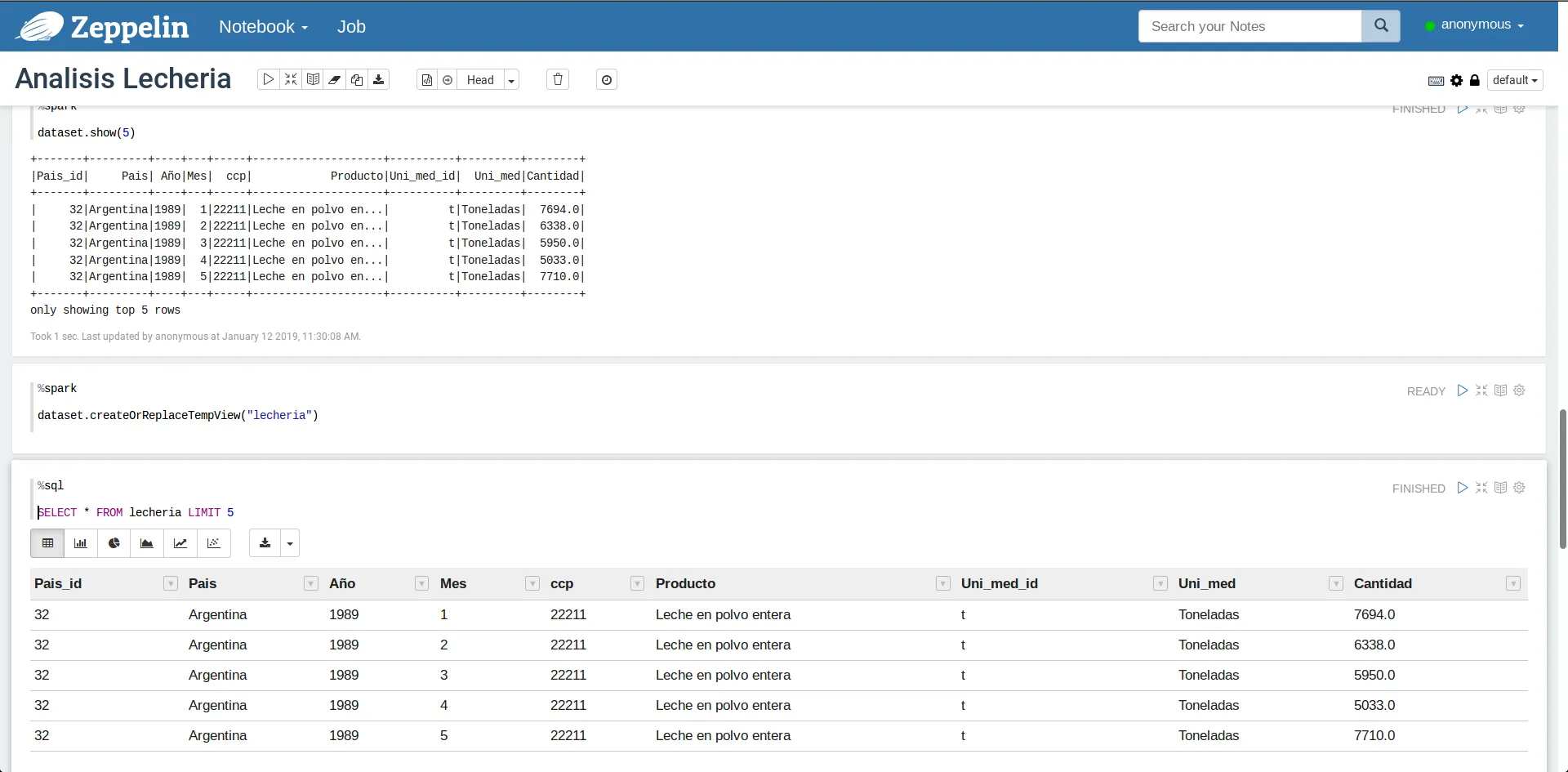 Mostrando los datos utilizando SQL
Mostrando los datos utilizando SQL
Se nota la diferencia entre los formatos (texto para el comando de Spark y html para SparkSQL). Zeppelin está pensado para hacer el trabajo mediante SQL mucho más sencillo.
Consultas SQL sencillas
Podemos arrancar con algunas consultas sencillas sobre SQL. Por ejemplo, para saber cuáles son los tipos de productos que podemos encontrar en el conjunto de datos, basta con la siguiente consulta:
SELECT DISTINCT(Producto) FROM lecheria
Esto nos arroja la siguiente información:
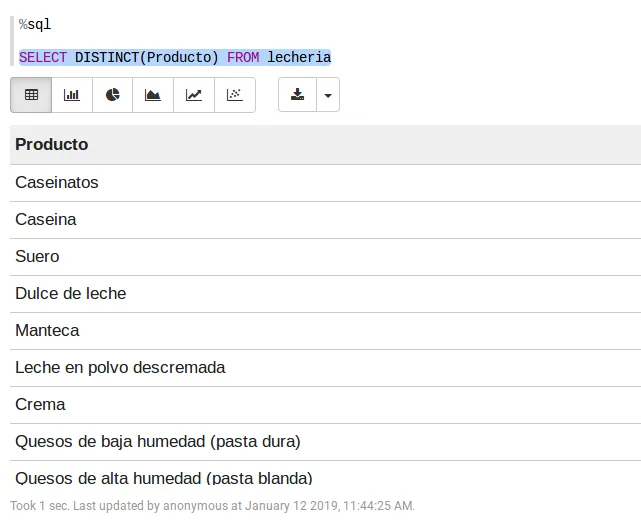 Resultados de una consulta SQL para obtener los distintos tipos de productos en el conjunto de datos
Resultados de una consulta SQL para obtener los distintos tipos de productos en el conjunto de datos
Ahora bien, si queremos ver la cantidad promedio de algún producto (e.g. "Yogur") en cada mes a lo largo de todas las entradas del conjunto de datos, podemos hacer la siguiente consulta:
SELECT Mes, AVG(Cantidad) AS Toneladas FROM lecheria WHERE Producto LIKE "Yogur" GROUP BY Mes
Eso nos mostrará una tabla nuevamente, que podemos acomodar un poco. Por ejemplo, si presionamos sobre el nombre de la columna, ordenará los datos de menor a mayor (si presionamos nuevamente lo hará de mayor a menor). En caso de ordenar por mes, puede que el orden sea 1, 10, 11, 12, 2, etc. Eso es porque está interpretando los datos como si fueran texto. A la derecha del nombre de la columna, una flecha hacia abajo permite definir que tipos de datos son.
Visualización básica con ayuda de Zeppelin
Ahora bien, si presionamos sobre el botón que muestra un gráfico de barras podremos pasar a ver una visualización básica de los datos. Si no muestra nada, simplemente abrimos el panel de settings y movemos los fields a sus respectivos lugares (e.g. Mes se arrastra a Keys y Toneladas a Values). Luego nos muestra un gráfico de barras con el promedio de toneladas por mes, similar al siguiente:
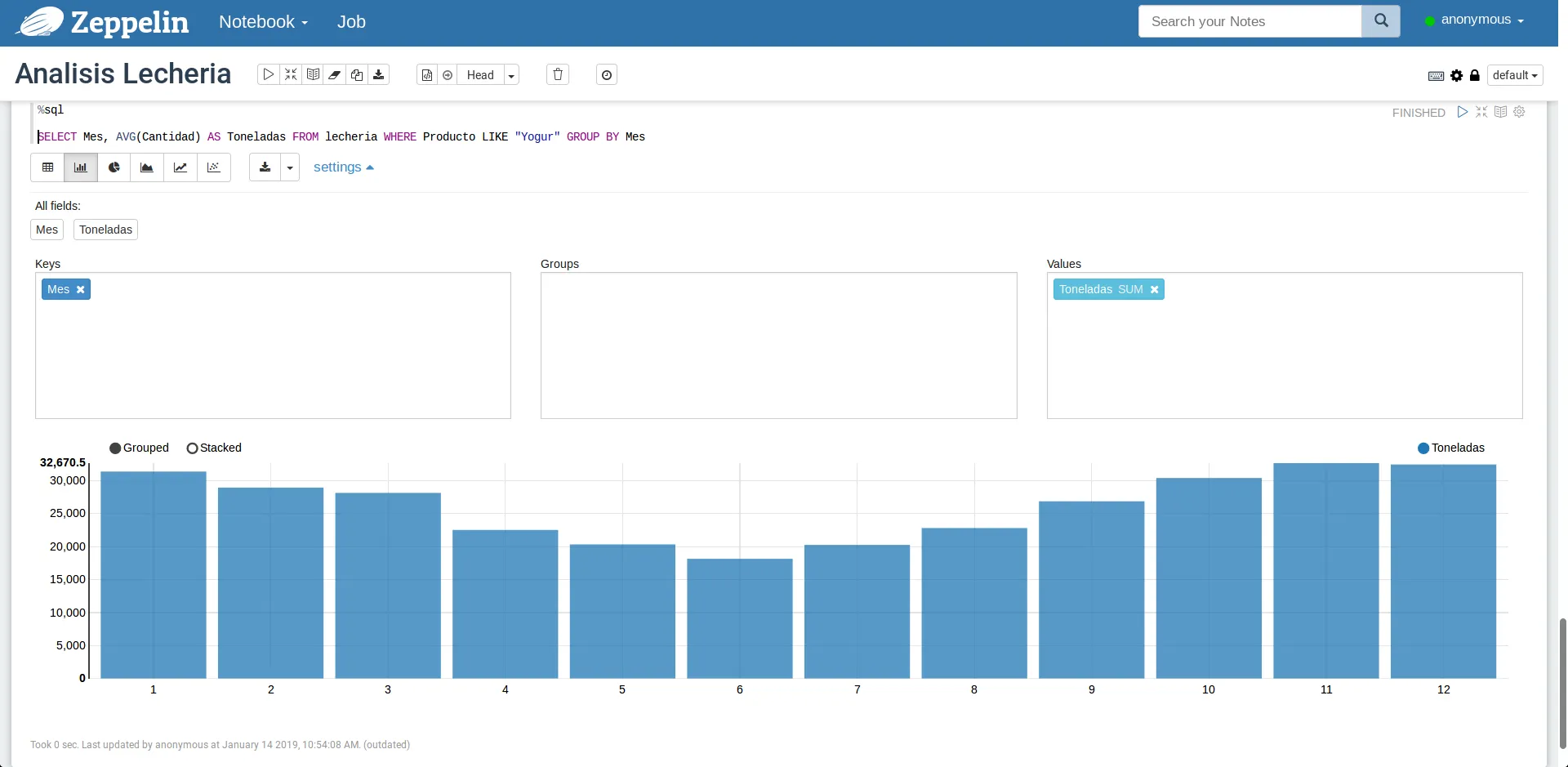 Visualizando datos con ayuda de Zeppelin
Visualizando datos con ayuda de Zeppelin
En el gráfico anterior vemos que la producción decae en los meses desde Abril y hasta Agosto (haciendo el pico en Junio). Algo natural puesto que es la época de invierno, donde las vacas dan menos leche.
Visualizaciones avanzadas
Zeppelin ofrece distintos tipos de visualizaciones sencillas: gráficos de barra, de torta, de línea, de área y de puntos. Además de que es interactivo con HTML y JavaScript por lo que se pueden hacer cosas mucho más complejas también. Sin embargo, muchas veces con los gráficos que podemos visualizar en Zeppelin nos es suficiente para hacer un análisis sencillo.
En si mismo, Zeppelin también tiene soporte nativo para cierta interactividad (pueden verlo al poner el puntero sobre las barras mostradas en el gráfico anterior). Incluso proveyendo gráficos muy interesantes que se pueden revisar interactivamente. Por ejemplo, si quisiéramos ver lo mismo que el caso anterior, pero esta vez para todos los productos posibles, podemos hacer la siguiente consulta SQL:
SELECT Producto, Mes, AVG(Cantidad) AS Cantidad FROM lecheria GROUP BY Producto, Mes
Luego, en el gráfico de barras, acomodamos los datos para que Mes siga estando dentro de Keys, Cantidad estará en Values y agruparemos por Producto al arrastrarlo dentro de Groups. El gráfico será parecido al siguiente:
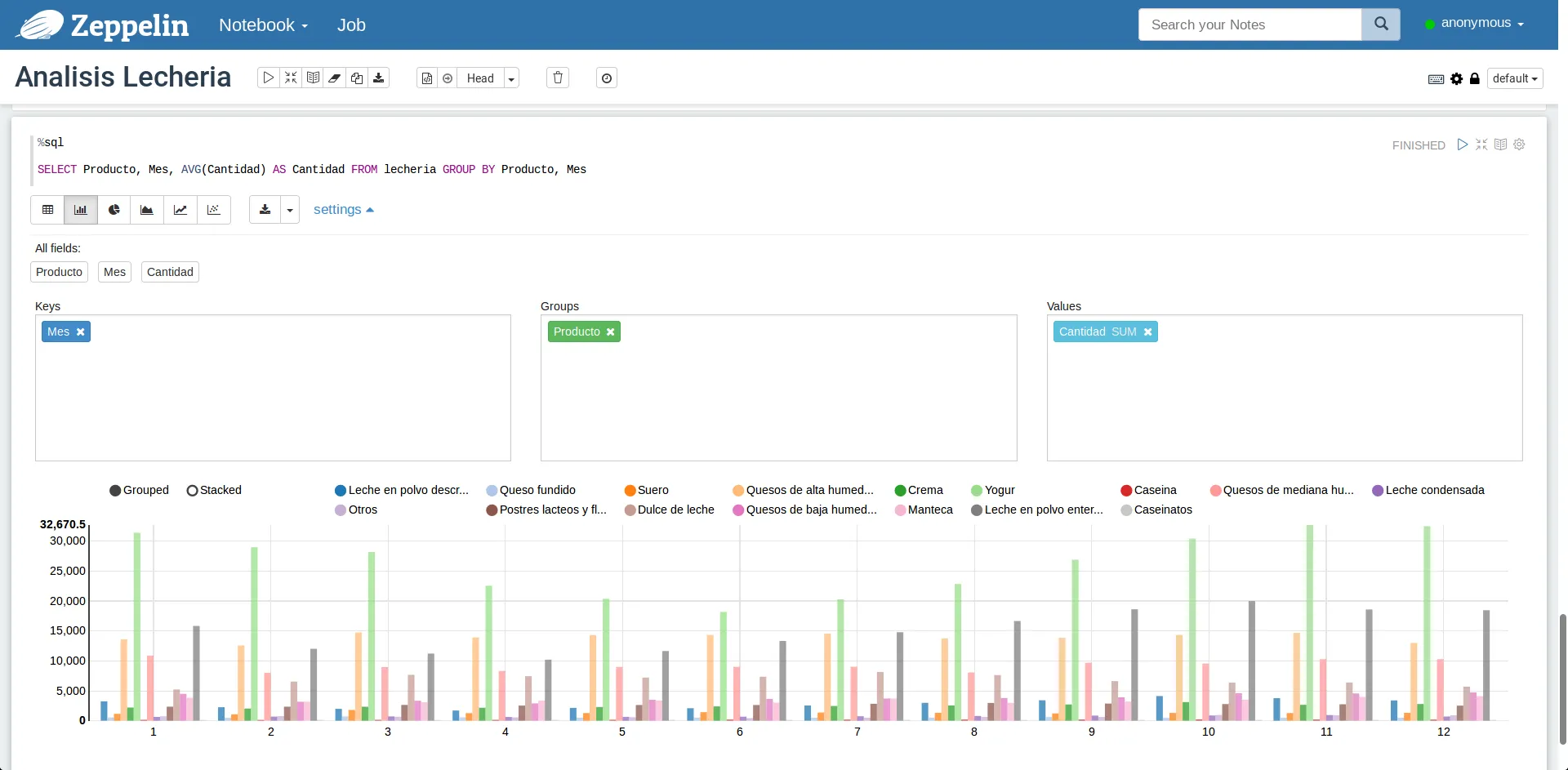 Visualizando cantidades agrupadas por producto
Visualizando cantidades agrupadas por producto
El gráfico, si bien es lindo, se hace difícil de interpretar con tanta variedad de productos disponibles. Sin embargo, podemos hacer uso de las herramientas mismas de Zeppelin para facilitar el análisis. Si presionamos una vez sobre cualquiera de los círculos de color al lado de los nombres de los productos, eliminaremos ese producto del gráfico (que se recargará). Si hacemos doble click a dicho producto, dejaremos ese producto sólo. Por ejemplo, haciendo doble click sobre “Crema”, obtendremos un gráfico similar al siguiente:
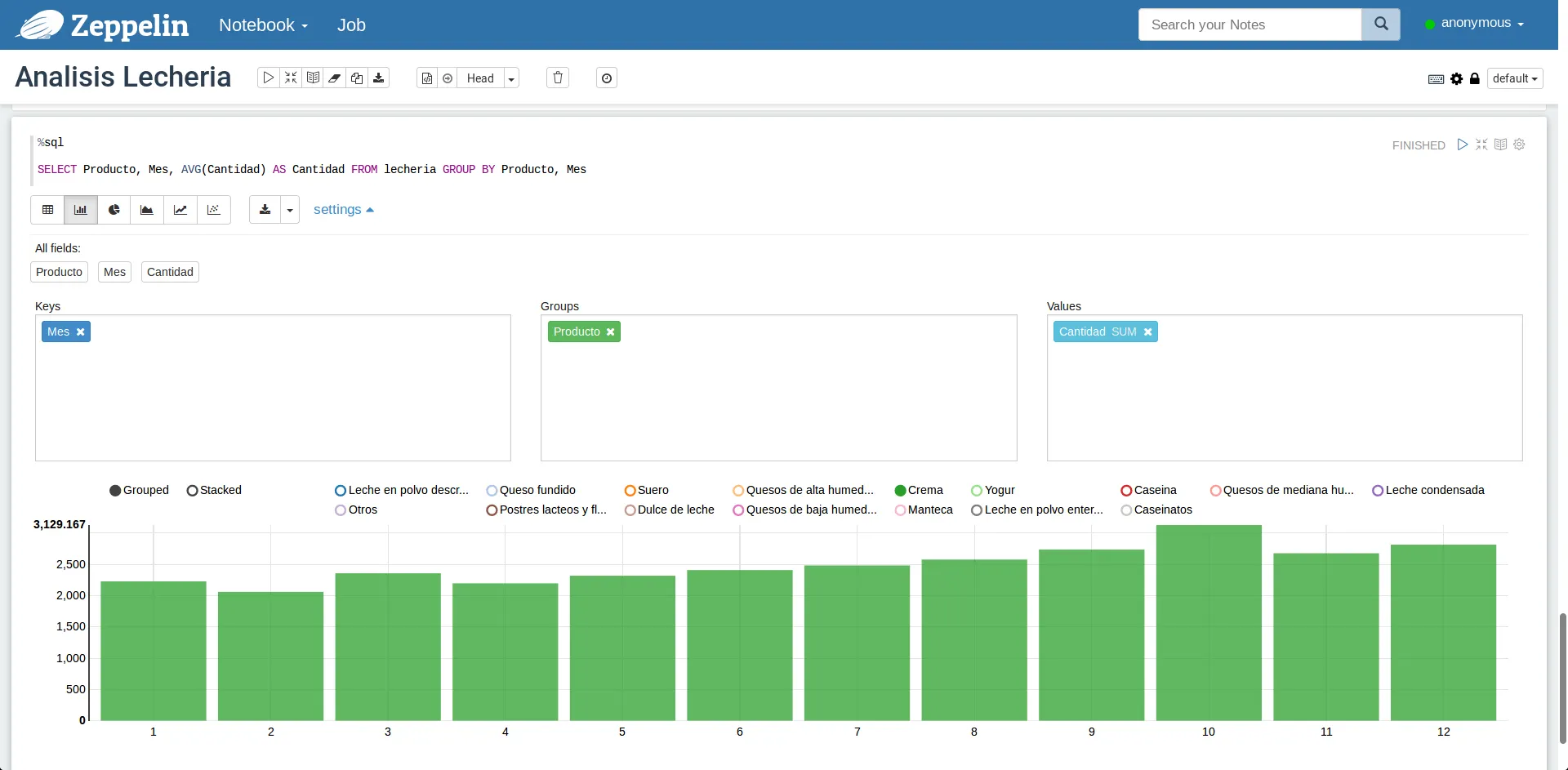 Gráfico de cantidad de crema promedio por mes
Gráfico de cantidad de crema promedio por mes
Luego, si por ejemplo queremos comparar eso con “Manteca”, basta hacer click en el item del producto y obtendremos un nuevo gráfico:
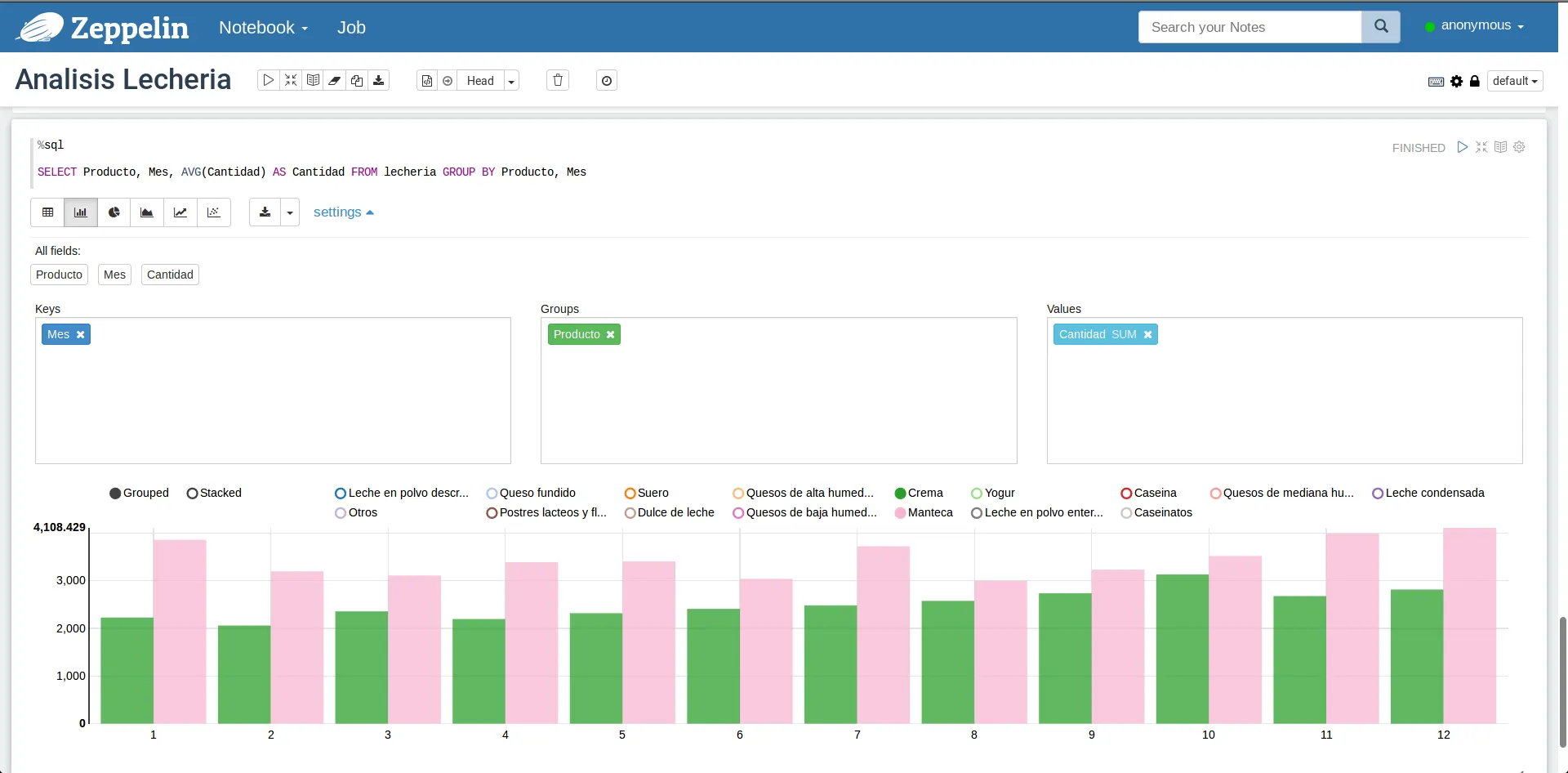 Cantidades comparadas entre crema y manteca
Cantidades comparadas entre crema y manteca
Por supuesto, este no es el único gráfico, y si nos movemos al gráfico de área podemos comparar nuevamente crema y manteca. Pero, podemos ver como evolucionan como parte de un todo (i.e. parte del 100% de la producción de derivados de la lechería) a lo largo del mes. Para esto cambiamos el tipo de gráfico a gráfico de área y lo marcamos como gráfico Expanded obteniendo algo así:
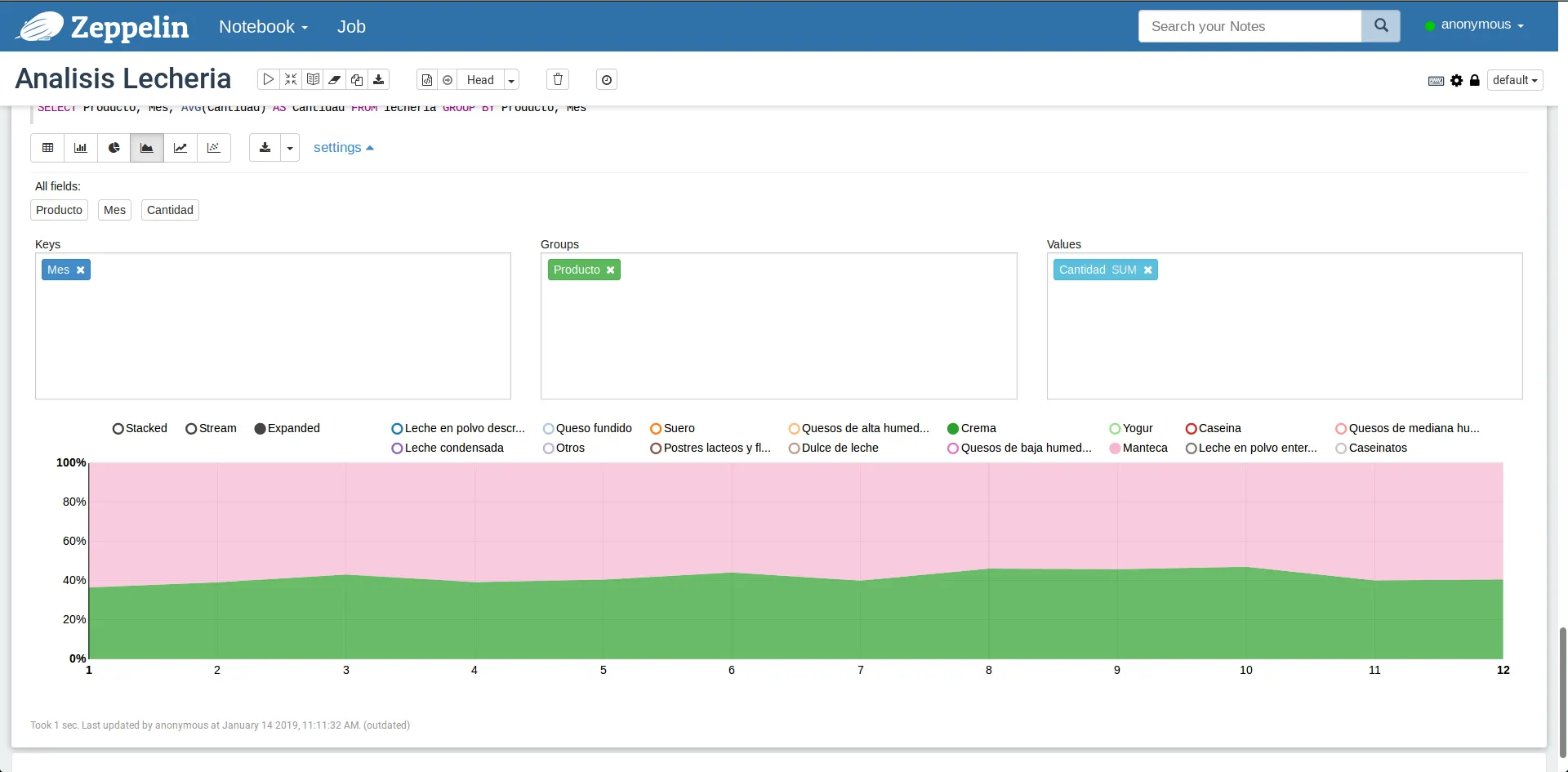 Comparación de producción de crema y manteca como parte de un todo
Comparación de producción de crema y manteca como parte de un todo
Finalizando
En fin, las posibilidades con SparkSQL y Zeppelin están limitadas por su imaginación a la hora de analizar datos, y su conocimiento de SQL y visualización. Hay muy buenos libros para aprender más acerca de esto que lo que yo puedo otorgar en unas pocas sesiones escritas en Medium. Les recomiendo que busquen y lean más al respecto. Si quieren una recomendación, a mi me gustaron mucho estos dos:
- Janert, Philipp K. Data analysis with open source tools: a hands-on guide for programmers and data scientists. "O'Reilly Media, Inc.", 2010.
- Grus, Joel. Data science from scratch: first principles with python. "O'Reilly Media, Inc.", 2015.
En la próxima entrega veremos algo de MLLib, la librería para hacer machine learning con Spark. Como siempre, gracias por leer!